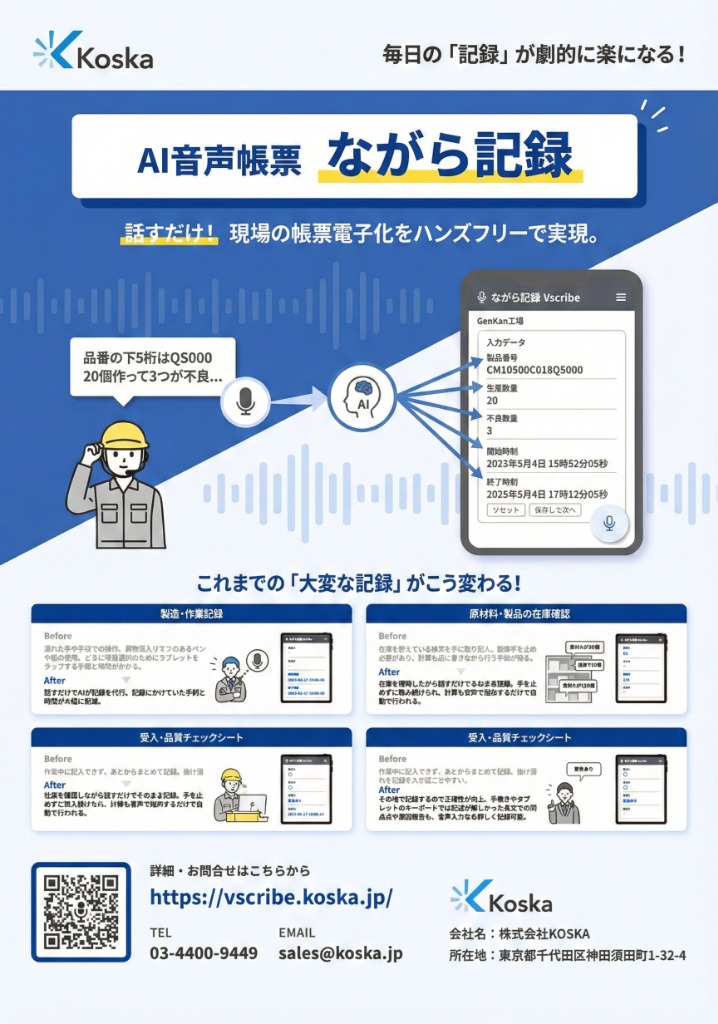
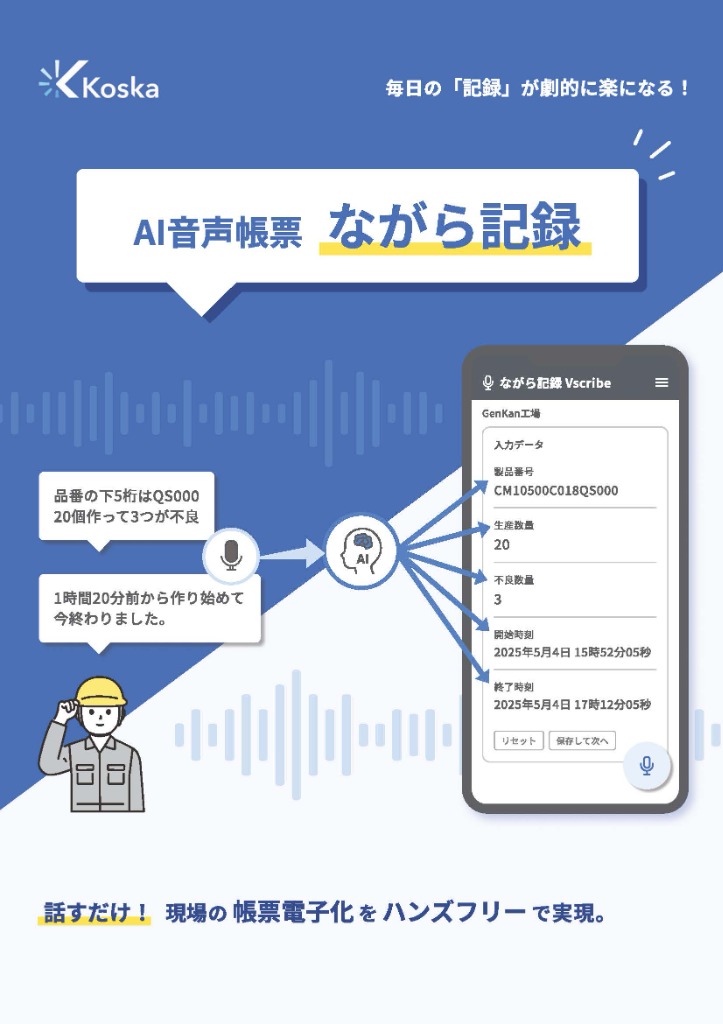
外国人作業者の記録は、母国語で話すだけでいい——AIが日本語の帳票に変える仕組み
日本語の
目次
「漢字の項目名が読めず、手が止まる」「備考欄が空欄のまま出てくる」——日本語の読み書きを前提にした帳票は、日本語に不慣れな作業者にとって重い負担になります。外国人材が活躍する現場で、こんな記録の悩みはありませんか。
その原因は、人ではなく、帳票の側にあります。
完璧な日本語の「読み書き」を前提にすれば、たしかに記録は難しくなります。漢字の品番を読み、専門用語を理解し、所見を日本語の文章で書く——これは日本語を母語としない人にとって、会話とは別次元の負担だからです。
でも、記録は「読み書き」でなくてもいい。母国語で話すだけで、管理者が読める日本語の記録に変える。それが、AIの音声入力ならできることです。この記事では、なぜそれが可能なのか、そして「画面を多言語に翻訳しただけ」のやり方と何が違うのかを、盛らずに解説します。
「言葉の壁」の正体は、メニューが日本語であることではない
多言語対応、と聞くと、多くの人が「アプリの画面を母国語に翻訳すること」を思い浮かべます。
でも、現場の記録で本当に厄介なのは、そこではありません。
人が言葉を使う力は、大きく2つに分かれます。「聞く・話す」と「読む・書く」です。そして日本語を母語としない人にとっては、この2つの難易度が大きく異なることがあります。日常会話は流暢でも、漢字の読み書きとなると負担が一気に増える——現場でよく見る光景です。
記録という行為は、この「難しいほう」に偏っています。
- 帳票の項目名(漢字)を読む
- 「異常あり/なし」をどう判断するか理解する
- 所見や数値を枠内に書く
画面のボタンやメニューを母国語にしても、この「読む・理解する・書く」の負担はほとんど残ります。だから、UIを翻訳しただけでは、壁は下がりきりません。
「言葉の壁」の正体
日本語を母語としない人にとって、2つの言語スキルの負荷は大きく異なることがある
日常会話はできる
- ・現場の指示が分かる
- ・口頭でのやり取り
- ・母国語ならなおさら得意
会話とは別次元の負担
- ・漢字の項目名を読む
- ・何を書くか判断する
- ・所見を日本語で書く
記録は 「読む・書く」 に偏っています。 だから画面(UI)を母国語に翻訳しても、壁は下がりきりません。 攻めどころは、得意な 「話す」 を記録の入り口にすることです。
逆に言えば、攻めどころははっきりしています。作業者が得意な「話す」を、しかもいちばん話しやすい母国語を、そのまま記録の入り口にすればいい。読み書きを迂回できれば、壁の大半は消えます。
(※帳票そのものを外国人作業者向けに設計し直す方法——やさしい日本語・選択式・マスタ連携——は、「外国人労働者が増える製造現場の記録課題と帳票電子化」で詳しく解説しています。本記事はその中の「母国語で話す」という入力の中身を掘り下げます。)
「画面を翻訳すればいい」が、現場で壊れる理由
「では画面を全部その国の言葉に翻訳すればいいのでは」と考えたくなります。
これは一見すると正攻法ですが、現場の記録ではいくつかの場所で壊れます。手段が悪いのではなく、翻訳という発想が、記録という仕事と噛み合っていないのです。
固有名詞・品番が、翻訳で壊れる。 品番・型番・図番・社内の独自呼称は、もともと「言葉」ではなく「識別子」です。翻訳にかけると、略称が一般名詞に化けたり、訳語の無い記号が音訳されたりして、同じものを指しているのに表記がずれます。製造・物流・建設では、品番1文字の取り違えが誤出荷や組み違いに直結します。翻訳を一枚かませること自体が、リスク源になります。
「何を書くか」は、翻訳されない。 項目名を訳せても、「異常あり/なし」をどの基準で判断するか、その欄に何を入れるべきかは、ラベルの裏にある暗黙知です。ラベルだけ母国語になっても、判断の中身は伝わりません。
言語の数だけ、様式の保守が増える。 対応言語ごとに帳票様式を作り直すと、項目を1つ直すたびに全言語版を直して回る必要があります。更新漏れが1つあれば、現場で「どの版が正しいのか」が分からなくなります。人員の多国籍化に、様式の保守が追いつきません。
母国語のまま保存すると、管理者が読めない。 作業者が母国語で入れて、母国語のまま記録に残すと、今度は日本語しか読めない管理者・監査側がそれを検証できません。後から人手で日本語に訳し直す二重管理が生まれます。
つまり「翻訳して表示する」だけの素朴なやり方は、入り口の見栄えは良くても、記録の出口(管理者が読め、監査に耐える日本語の一次記録)まで届きません。
AIならではの差は「母国語の発話を、日本語の帳票値に変える」こと
ここからが本題です。
「母国語の話し言葉を理解する」こと自体は、実はもう特別ではありません。ChatGPTやGeminiのような汎用の大規模AIは、世界中の多くの言語を理解します。隠す話でもありません。
差がつくのは、その先です。
理解した言葉を、「現場の帳票」という決まった構造に、間違いという地雷を踏まずに落とし込む——この作り込みこそが、製品の本当の仕事です。ながら記録が力を注いできたのも、汎用AIそのものではなく、その「外側」です。
2つの「多言語対応」の分かれ道
画面を翻訳するのか、発話そのものを記録に変えるのか
現場で壊れる
- ✕読む・書く・判断の負担は残る
- ✕品番・固有名詞が翻訳で壊れる
- ✕言語ごとに様式を作り直す保守地獄
- ✕母国語のまま保存 → 管理者が読めない
現場で効く
- ◎読み書きを迂回できる
- ◎固有名詞はマスタ照合で正式値に
- ◎様式は1つ、データは日本語で一元化
- ◎管理者が読める日本語の記録が残る
差がつくのは「翻訳」ではなく、発話を帳票の構造に落とし込む“外側”の作り込み
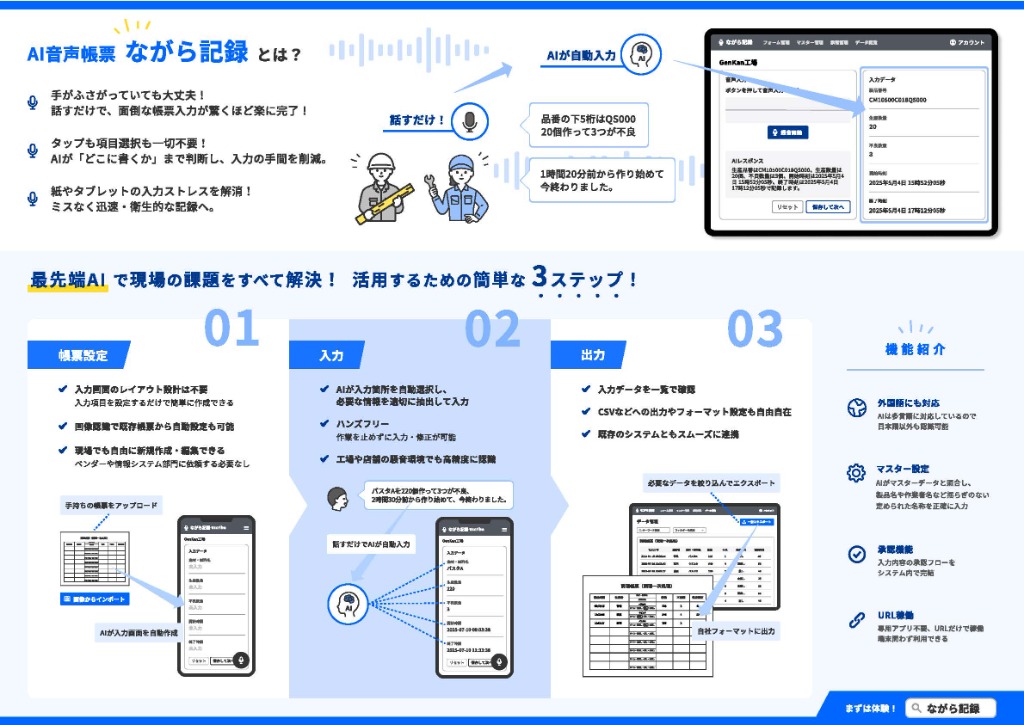
具体的には、母国語の発話が記録になるまでに、いくつもの層が働きます。手品ではなく、地道な作り込みです。
- 話した内容を、帳票の項目に振り分けます。文字起こしして終わりではありません。「数量は120、外観はOK、担当は田中」と思いつくまま話しても、それぞれが正しい欄に、正しい型で入ります。項目をタップして選んでから話す必要はありません。
- 言いやすい呼び名を、正式な値に直します。人は正式名称を完璧には言いません。話した言葉を、登録済みのマスタ(品名・部品名などの台帳)とあいまいに照合し、表記のゆれを正式な表記に寄せます。日本語にしかない品番や社内独自の呼称も、台帳に登録しておけば、口にした言葉から正しい値に結びつきます。
- 数字や単位を、現場の言い方のまま受け取ります。「2キロ」と言えば数値の欄に、「1時間前」と言えば時刻に。表現を整えてから話す必要はありません。
- 間違えても、話して直せます。確定した値は、その後の発話で勝手に上書きされないよう守られます。誤って認識されても「さっきの担当を佐藤に変えて」と言い直せば、その欄だけが直ります。一度の間違いが、入力済みの他の欄を巻き込んで壊すことはありません。
- 関係ない音は、書き込みません。現場は雑談や機械音にあふれています。記録に関係のない音声は取り込まないようにして、誤って欄に入るのを防ぎます。
これらは「翻訳API」や「画面の多言語化」では出てこない層です。汎用AIを一度呼ぶだけの素朴な実装とも、ここで分かれます。誤りが起きることを前提に、起きても崩れないように受け止める——その多層の作り込みが、騒がしい現場でも「読み書きせずに、正しい記録が残る」を支えています。
(※声を「現場で使える帳票」に変えるまでの作り込みについては、「どこも裏側は同じAIでしょ?——いいえ、違うんです」でも別の角度から解説しています。)
だから、管理者が読める「日本語の記録」が残る
この仕組みの一番うれしいところは、出口です。
作業者は自分がいちばん話しやすい言語で話す。けれど帳票に残るのは、日本語の、正式な値です。
管理者は、いつもどおり日本語で記録を読めます。誰が・いつ・何を記録したかがデータとして残り、Excel/CSVに出力すれば、品質管理台帳や監査の証跡にそのまま乗ります。言語ごとに記録がバラバラにならず、1か所に日本語でまとまります。
作業者は「いちばん得意な言葉」で話すだけ。管理者は「いつもの言葉」で読むだけ。両者の言語を、記録のデータがつなぎます。 これが、画面を翻訳するだけのやり方では届かなかった最終形です。
母国語で話すと、日本語の記録になるまで
作業者は得意な言葉で話すだけ。管理者はいつもの言葉で読むだけ
AIの“外側”の作り込み
現場の地雷を踏まないための工夫(順番ではなく“何が起きるか”)
正直に言う、できることと、その境界
ここまでを「だから何でも自動で完璧に入る」と読まれると困るので、境界を正直に書きます。差別化は、盛らないほうが伝わると考えています。
- 音声認識の精度は、言語・話し方・周囲の騒音・専門用語の有無などによって変わります。設計上は揺れに強くしていますが、「どんな環境・どんな話し方でも100%」ではありません。だからこそ、導入前に無料の現場テストで、実際の作業者の声で確かめることをおすすめしています。
- 日本にしかない品番・型番・社内特有の呼称は、マスタ登録が前提です。口にした言葉から正しい値に結びつけるには、台帳の用意がいちばん効きます。必要なら、読み(ふりがな)や母国語を併記しておくと、さらに当たりやすくなります。
- 画面(UI)の表示は、日本語・英語の2言語です。ベトナム語・中国語などへの画面切り替えは、現時点では行っていません。ただし作業者は画面を読むより「話す」のが中心なので、運用上は項目名の後ろに母国語や英語を括弧で併記する工夫で十分に回せます。
- 対応できる言語は、裏側のAIが理解できる範囲に依存します。需要の多い主要な言語(英語・中国語・ベトナム語など)は比較的安定して扱えますが、検証経験の少ない言語は事前の確認が要ります。
- 最後の確認は、人が行う前提です。AIが入れた内容を、現場や管理者が最終チェックする運用を組み合わせることで、記録の品質を保てます。
「全自動の魔法」ではありません。けれど、「日本語の読み書きが前提だから、正確な記録は難しい」という地点からは、確実に一歩も二歩も先へ進めます。
よくある質問(FAQ)
外国人作業者の音声入力について、商談で実際に多くいただく質問をまとめました。
Q1. なまりや方言があっても、ちゃんと認識されますか?
設計上は、言い間違いや訛りがあっても必要な情報だけを拾うようにしていますが、「どんな訛りでも100%」とは言えません。数字や「可/不可」のような定型は比較的安定して入り、日本特有の固有名詞や複雑な語は揺れやすい、という傾向があります。精度は現場の環境や話し方に左右されるため、無料の現場テストで、実際の作業者の声で確かめていただくのが確実です。
Q2. 画面(アプリ)は、その国の言葉で表示されますか?
画面表示は日本語・英語の2言語です。ベトナム語・中国語などへの全画面の切り替えは、現時点では行っていません。ただ、外国人作業者の使い方は「画面を読む」より「話す」が中心になります。項目名の後ろに母国語や英語を括弧で併記しておけば、「ここに何を入れればいいか」は伝わり、内容は母国語で話して日本語に変換できます。
Q3. 言語ごとに帳票を分けて作らないといけませんか?データはバラバラになりませんか?
入力は何語で話しても、帳票に残るのは日本語の値で、データは1か所にまとまります。出力も1つにまとめられます。なお、1枚の同じ記録表を複数言語の作業者がまったく同じように使うことには限界があり、より正確を期すなら言語ごとに帳票を分ける運用もあります。その場合でも、出力されるデータは統合できます。
Q4. 母国語で話して日本語に変換する機能に、追加費用はかかりますか?
母国語で話すと日本語に変換して帳票に入る、という仕組み自体に、特別な追加プランは必要ありません。話していただくだけで変換されます。
Q5. 品番や自社特有の品名も、正しく入りますか?
はい、しっかり入ります。日本にしかない品番・型番・社内特有の品名も、あらかじめマスタ(台帳)に登録しておけば、口にした言葉から正しい正式名称に結びつきます。ポイントは、正式名称だけでなく、現場で使う読み(ふりがな)や略称、必要なら母国語もマスタに併記しておくこと。そうすれば、作業者は正式名称を正確に発音する必要はなく、いつもの言いやすい呼び方で話すだけで、帳票には正しい正式名称が入ります。固有名詞こそ、マスタ登録がいちばん効果を発揮するところです。
まとめ|「読み書き」を迂回すれば、言葉の壁は記録から外せる
外国人作業者の記録が難しいのは、本人の能力の問題ではありません。記録の仕組みが「日本語の読み書き」を前提に作られているからです。
- 本当の壁は「読む・書く」。 画面を多言語に翻訳しても、項目名を読み、判断し、書くという負担は残ります。
- 攻めどころは「話す」。 外国人作業者がいちばん得意な「話す」、しかも母国語を、記録の入り口にすれば、壁の大半を迂回できます。
- AIならではの価値は「外側」にある。 母国語の発話を、帳票の項目へ振り分け、マスタで固有名詞を解決し、誤認識を受け止め、関係ない音を弾く。この作り込みが、画面翻訳や単なる翻訳APIとの差です。
- 出口は、管理者が読める日本語の記録。 作業者は得意な言葉で話し、管理者はいつもの言葉で読む。記録のデータが両者をつなぎます。
- 盛らない。 精度は環境と話し方で揺れ、固有名詞はマスタ登録が前提で、最後は人が確認します。だからこそ、まずは現場テストで確かめてください。
外国人材は、これからの製造・物流・建設の現場を支える存在です。その人たちが「ミスをして怒られるのでは」と不安を抱えずに、得意な言葉で正確な記録を残せる環境は、品質と定着の両方への投資になります。
母国語で話すだけで日本語の記録になる仕組みを、自社の帳票で試してみたい方は、ぜひ資料請求やお問い合わせ、無料の現場テストにてご確認ください。