音声入力はAIでどう変わった?70年の技術史から読み解く、従来型とAI音声認識の原理的な違い
1952年の

【結論】従来の音声入力とAI音声入力の原理的な違い
従来の音声入力は、人間が手動で設計したルールに基づき「音波の波形を切り取って単語に変換する」ルールベースの処理でした。一方、現在のAI音声入力は、膨大なデータからAI自身がパターンを学習し、「会話全体の文脈から意味を推論してテキストを生成する」学習ベースの処理へと進化しています。この原理的な違いこそが、騒音の激しい現場や複雑な専門用語に対する圧倒的な認識精度の差を生み出しているのです。
音声入力技術は、ある日突然完成した魔法ではありません。私たちが現在スマートフォンや建設・製造現場のタブレットで当たり前のように使っている高精度な「音声認識 AI」の裏側には、世界中の研究者たちが挫折と発見を繰り返しながら挑み続けた70年にも及ぶ長い歴史が存在します。
「昔のカーナビの音声入力は全く使い物にならなかったのに、最近のAI音声入力はなぜこんなに賢いのか?」
本記事では、製造業・物流業・建設業などの現場責任者やDX推進担当者に向けて、音声認識技術の進化の歴史を時系列で辿りながら、従来型とAI型の原理的な違いを徹底的に解説します。単なるIT用語の羅列ではなく、技術の変遷をひとつの物語として読み解くことで、最新のAI音声入力がいかにして「現場の過酷な実務に耐えうる水準」へと到達したのかが、深く腑に落ちるはずです。明日から現場でAIツールを導入する際の確固たる判断材料として、ぜひご活用ください。
第1章: 音声認識の歴史 ― ルールベースの時代(1952年〜1990年代)
機械が人間の言葉を理解するという夢は、コンピューターの黎明期から存在していました。しかし、その道のりは決して平坦なものではありませんでした。初期の研究者たちは、人間の声という極めて曖昧で変化しやすいデータを、いかにして数学的に処理するかに苦心していました。
「音を聞き分ける」ことへの最初の挑戦
1952年、アメリカのベル研究所の研究者たちは、部屋を埋め尽くすほどの巨大な電子装置の前に立っていました。彼らが開発した音声認識システム「Audrey(Automatic Digit Recognizer)」が誕生した瞬間です。記録に残る限り、機械が人間の声を自動認識した最初の事例とされています[1]。
Audreyは、人間が電話の受話器越しに発声した「0」から「9」までの数字を聞き分け、該当する数字のランプを点滅させるという画期的な装置でした。しかし、その仕組みは極めて限定的でした。認識できたのはわずか10個の数字のみであり、さらに開発者自身など、事前に発声パターンを調整された特定の「単一話者」の声にしか対応できませんでした。
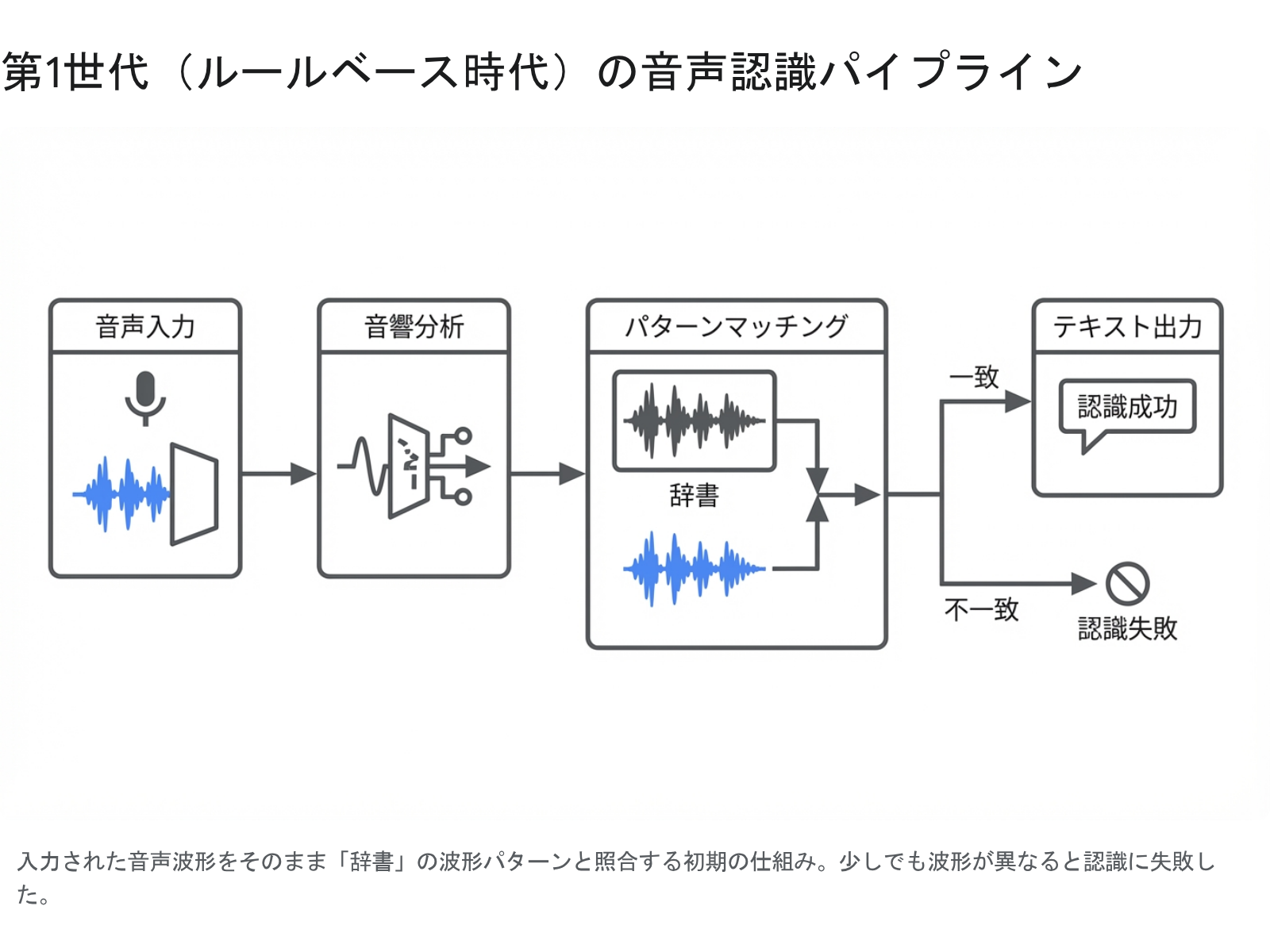
この時代に採用されていたのは「パターンマッチング」と呼ばれる原始的な手法です。入力された音声の波形から「フォルマント(声の響きの特徴となる周波数帯域)」を抽出し、あらかじめアナログメモリに保存されている「正解の波形パターン」と直接照らし合わせる仕組みでした。これは「同じ言葉なら同じ波形になるはずだ」という単純な前提に基づくアプローチです。しかし、現実の人間の音声は、話者の骨格、その日の体調、感情、そして周囲のノイズによって無限に変化します。そのため、登録された波形と少しでもズレが生じると、Audreyは途端に認識に失敗してしまいました。
DARPAの大規模プロジェクトと「HMM」の台頭
1970年代に入ると、アメリカ国防総省の国防高等研究計画局(DARPA)が軍事利用を見据え、大規模な音声理解研究(SUR)プログラムに数百万ドルの資金を投じます。このプログラムの最大の成果の一つが、1976年にカーネギーメロン大学(CMU)が開発した「Harpy(ハーピー)」システムです。
Harpyは、約1,000語(平均的な3歳児の語彙力に相当)を認識し、連続した文章を理解できるシステムへと進化を遂げました。「ビームサーチ」と呼ばれる探索アルゴリズムを導入し、膨大な音声の可能性の中から「最も確率の高い正解ルート」だけを効率的に絞り込むことで、劇的な速度向上と精度向上を果たしました。
そして1980年代、音声認識の歴史を決定づける極めて重要な数学的手法が導入されます。それが 「HMM(隠れマルコフモデル:Hidden Markov Model)」 です。1989年にLawrence R. Rabinerが発表した決定版チュートリアル論文により、HMMは瞬く間に音声認識の世界標準となりました。
HMMは、単純な波形の比較ではなく、「確率を使って『次に来る音』を予測する手法」です。例えば、「お」という音が聞こえたとき、次に来る音は「あ」よりも「は」や「か」である確率が高い、といった具合に、音声信号を確率的な状態の推移として捉えます。これにより、従来のような「波形をそのまま比較する」力技から、「音声を音素(発音の最小単位)に分解し、辞書や文法規則と組み合わせて、統計的に最も確からしい単語列を出力する」という高度な計算パイプラインが完成しました。
第1世代の限界:「使えない音声入力」の烙印
HMMの導入により音声認識は大きく前進しましたが、根本的な課題は未解決のままでした。
当時の処理方式は、音響を分析し、音素を抽出し、辞書と照合するという各プロセスを、人間が「この音はこういう特徴があるはずだ」と手作業でルール化してつなぎ合わせたものでした。そのため、以下のような致命的な限界がありました。
- 激しい話者依存性: システムを利用する前に、特定の人の声に合わせて長時間のチューニングを行わなければ精度が出ない。
- ノイズへの極端な脆弱性: 現場の機械音、風の音、さらには周囲の雑談が少しでも混ざると、人間が設定した音響特徴のルールから外れてしまい、全く認識できなくなる。
- 文脈理解の欠如: 同音異義語(「機械」と「機会」など)の区別が難しく、意味の通らない支離滅裂な文章が頻発する。
この時代の音声認識は、防音設備のある静かな部屋で、はっきりと、マイクに口を近づけて話すという「機械の都合に人間が合わせる」使われ方しかできず、騒音が飛び交う製造現場や建設現場では「とても使えないおもちゃのような技術」というイメージが定着してしまいました。
第2章: ディープラーニング革命 ― AIが音声認識を変えた(2006年〜2020年頃)
1990年代から2000年代前半にかけて、コンピューターの計算能力は飛躍的に向上したものの、音声認識の認識精度は頭打ちとなり、「AIの冬」と呼ばれる停滞期を迎えていました。人間の手でこれ以上精巧なルールを作ることは限界に達していたのです。しかし2006年、Geoffrey Hintonらが発表した画期的な論文によって、厚い氷が溶け始めます。彼らが提唱した「ディープビリーフネットワーク(DBN)」の高速学習アルゴリズムは、それまで計算が重すぎて不可能だと思われていた多層ニューラルネットワーク(ディープラーニング)の学習を現実的なものにしたのです。
2012年の衝撃:音響モデルのブレイクスルー
音声認識の歴史において、真の意味で「革命」と呼べる瞬間が2012年に訪れます。Geoffrey Hintonを中心とする研究チームが、通常は激しく競い合っているGoogle、Microsoft、IBMという巨大IT企業の研究者たちと共同で発表した論文「Deep Neural Networks for Acoustic Modeling in Speech Recognition」です。
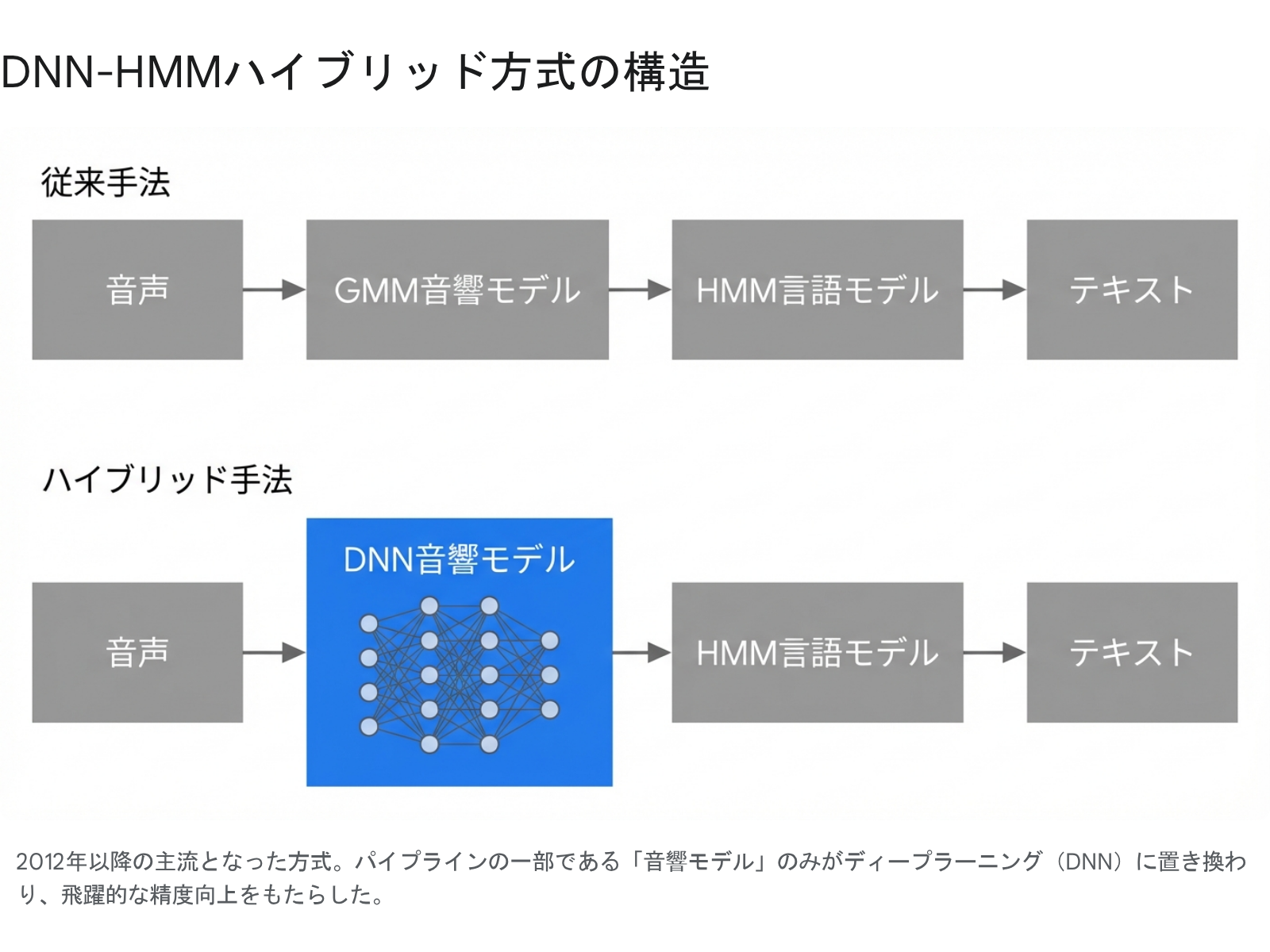
この論文が発表されたことで、音声認識の研究パラダイムは一変しました。彼らは、従来の音声認識パイプラインで「音の特徴」を捉えるために使われていた「GMM(ガウス混合モデル)」という人間の手による統計的手法を、 「DNN(ディープニューラルネットワーク)」 に丸ごと置き換えたのです。
人間が手動で設計した特徴量のルールに従うのではなく、DNNに大量の音声データを入力し、機械自身に「この複雑な音の波形は、どの音素に対応するのか」というパターンを自動で学習させました。その結果は驚くべきものでした。従来のGMMベースの手法と比較して、音声認識のエラー率(WER)が一気に33%近くも削減されるという、従来手法の漸進的な改善幅を考えると、異例の改善幅でした[4]。
「DNN-HMM ハイブリッド方式」の仕組み
この転換期に確立されたのが「DNN-HMM ハイブリッド方式」です。
従来型とAI型の仕組みの違いをここで明確に整理しましょう。
- 従来(GMM-HMM): 人間が「声の特徴はこうだ」と数式モデル(GMM)を設計し、音声をそのルールの枠組みに当てはめて分類する。
- AI導入(DNN-HMM): 膨大な音声データから、AI(DNN)が自ら「こう聞こえたらこの音素だ」という複雑な特徴を自動で発見し獲得する。
DNNは、背後にノイズが混ざった音声や、強い訛りのある音声など、多様なバリエーションのデータを大量に飲み込み、人間には設計不可能なほど複雑で微細なパターンを見つけ出すことに長けていました。この技術的ブレイクスルーこそが、2011年に登場したSiriや、その後のGoogle Now、Googleアシスタントといった、私たちが日常的に使うスマートフォン音声入力の裏側を支えるコア技術となりました。
第2世代の限界:ツギハギのパイプラインによる情報損失
ディープラーニングの導入により「音を正確に聞き取る」能力は飛躍的に向上しました。しかし、この段階では「音声を意味レベルで理解するAI」にはまだ至っていませんでした。
なぜなら、システム全体が依然として「音響分析」「音響モデル(DNN)」「言語モデル(HMM)」「発音辞書」という別々のパーツをブロックのように組み合わせたパイプライン構造のままだったからです。各パーツはそれぞれ独立して最適化されており、システム全体を通した最適化(全体最適)は行われていませんでした。
これは例えるなら、「耳が極めて良い人(音響モデル)」と「文法規則だけを知っている人(言語モデル)」が、別々の部屋に分かれて伝言ゲームをしているような状態です。そのため、接続部分での情報ロスが必ず発生し、「音としては正確に聞き取れるが、文脈がおかしい同音異義語を訂正できない」「言い間違えをそのまま文字にしてしまう」といった限界を抱えていました。
さらに致命的だったのは、現場の製造用語や建設現場の専門用語を入力しようとしても、「発音辞書」に登録されていない未知の単語(アウトオブボキャブラリー)は絶対に認識できないという点です。結局のところ、現場の複雑な実務運用に耐えるには、まだ大きな壁が立ちはだかっていたのです。
第3章: End-to-End モデル ― 音声を「一気に」テキストへ(2014年〜現在)
ツギハギだらけのパイプラインの限界を打ち破るため、研究者たちは次なる野心的な目標を掲げました。「音声波形を入力し、中間の煩雑な処理を一切省いて、直接テキストを出力する単一の巨大なAIモデルを作れないか?」という発想です。これが、現代の音声認識の基盤となる 「End-to-End(エンドツーエンド)」 モデルの登場です。
全てを一つのネットワークで処理する
2014年、Alex GravesとNavdeep Jaitlyによって、リカレントニューラルネットワーク(RNN)を用いたEnd-to-End音声認識の画期的な論文「Towards End-to-End Speech Recognition with Recurrent Neural Networks」が発表されました。
彼らは、CTC(Connectionist Temporal Classification)と呼ばれる特殊な目的関数を導入しました。従来の手法では、「この0.1秒の音声フレームはどの音素か」という細かい正解ラベルを人間が膨大に用意して学習させる必要がありました。しかしCTCを使うことで、入力された音声データの長さと、出力すべきテキストデータの長さが一致していなくても、AI自身が「どのタイミングでどの文字を発音しているか」を自動的に紐付けて学習できるようになったのです。
これにより、人間による音素への分解や、手動で作成した辞書との照合といった中間処理が不要になりました。「入力から出力まで一気通貫」で学習・処理する、真に自律的なアーキテクチャが実現したのです。
Attention機構とTransformerの波及
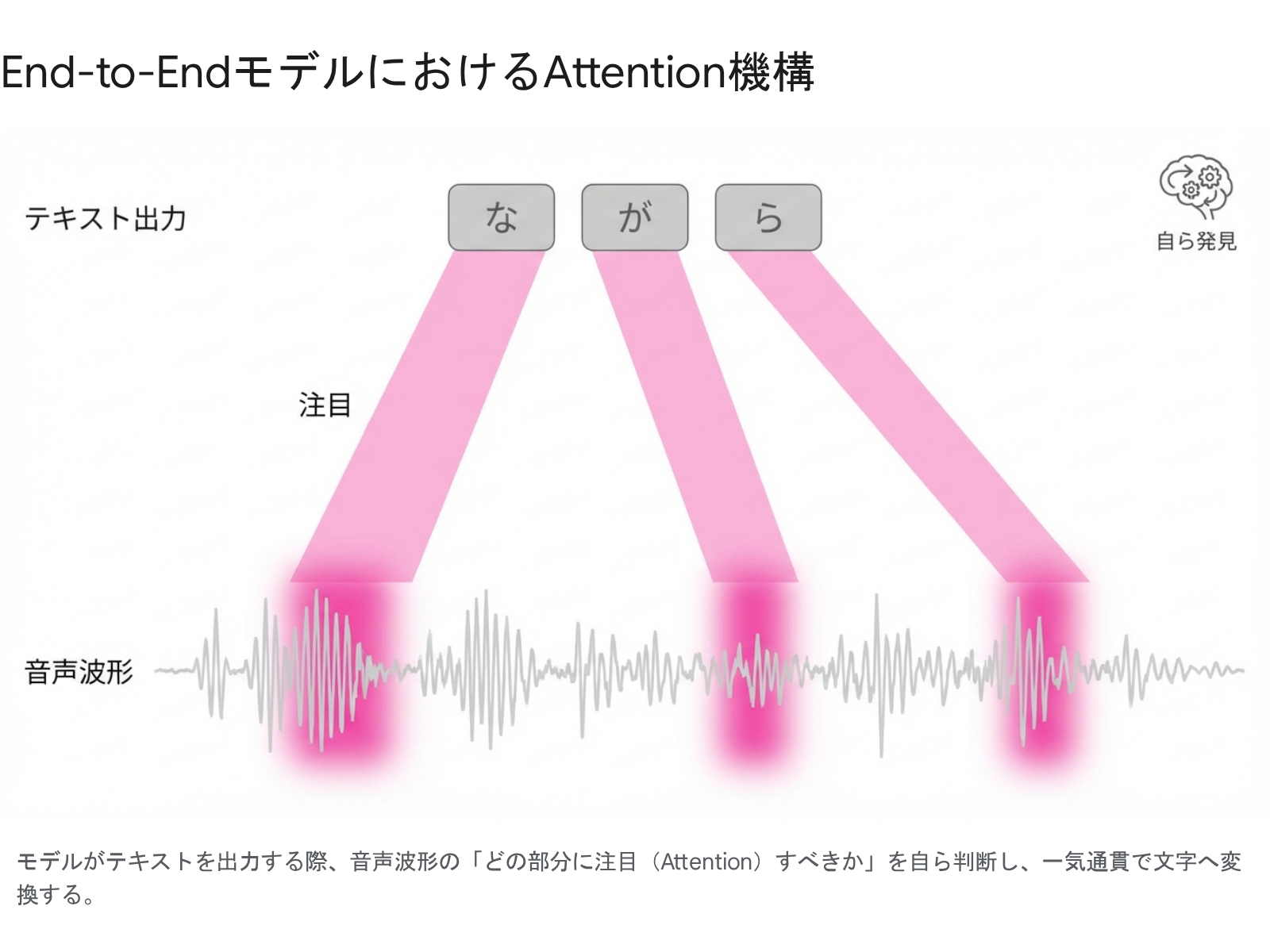
2016年には、William Chanらが「Listen, Attend and Spell (LAS)」というアーキテクチャを発表します。これは「Attention(注意)機構」を音声認識に初めて本格的に取り入れた画期的なものでした。
LASは、人間の脳が会話を聞く時のように「いま出力しようとしている文字に対して、入力された長い音声データの『どの部分』に強く注意を向けるべきか」をモデル自身が学習します。このAttentionの概念は、翌2017年にGoogleの研究者らによって発表された伝説的な論文「Attention Is All You Need」(Transformerの誕生)によってAI全般のデファクトスタンダードとなり、音声認識技術の進化をさらに数段上の次元へと加速させました。
OpenAI Whisperの衝撃と現場水準の達成
そして2022年、End-to-Endモデルの集大成とも言える巨大なシステムが登場します。ChatGPTの開発元であるOpenAIが発表した 「Whisper」 です。
Whisperは、これまでの音声認識モデルとは桁違いの「68万時間」というインターネット上の膨大な音声データ(多言語・マルチタスク)を読み込み、事前学習されました。英語だけでなく99もの言語に対応し、ゼロショット(特定の業務や環境向けに追加の微調整を行わない状態)のままで、LibriSpeechという標準的なテストにおいてWord Error Rate(単語エラー率)6.7%を叩き出し、プロの人間による文字起こしに匹敵する認識精度と堅牢性を達成しました。
従来のパイプライン方式では、各パーツの接続部分で必ず情報が失われていましたが、WhisperのようなEnd-to-Endモデルでは最適化がシステム全体に及びます。その結果、これまでのシステムでは致命的だった「工場内の機械の稼働音」や「屋外の風切り音」などのバックグラウンドノイズに対しても、信じられないほどの耐性を獲得しました。データによれば、信号対雑音比(SNR)が10dBを下回るような強い騒音環境下において、従来モデルの精度が急激に低下するのに対し、Whisperは高い精度を維持することが実証されています。
さらに、単に「聞いたままの音を無機質に文字にする」だけでなく、句読点の自動挿入や、「えー」「あの」といったフィラー(言い淀み)の自動除去まで、モデルの内部で極めて自然に処理されるようになりました。
第4章: マルチモーダルAI ― 音声を「意味ごと理解する」時代(2023年〜)
End-to-Endモデルによって音声認識は極めて高い精度を獲得し、ついに実用レベルに達しました。しかし、AIの進化はそこで止まりませんでした。2023年以降、音声認識は「音をテキストに変換する技術(STT:Speech-to-Text)」という枠組み自体を根本から超えようとしています。
それが 「マルチモーダルAI」 の時代です。
「文字に変換する」から「意味を理解する」へ
これまでのWhisperを含むすべてのAI音声認識は、あくまで「音声を高精度なテキストに変換し、そのテキスト化された文字列を別のAI(LLMなど)が読み込んで処理する」という直列のプロセスを踏んでいました。しかし、この方式には構造的な欠陥があります。それは、人間の声に含まれるトーン、感情、ため息、言葉の強調といった「テキスト化する過程でこぼれ落ちてしまう非言語情報」が失われてしまうことです。
この最後の壁を突破したのが、テキスト、画像、音声、動画といった異なる形式の情報をネイティブに統合処理できるマルチモーダルAIです。
2023年にGoogle DeepMindが発表した 「Gemini」 は、音声をいったんテキストに変換してから理解するのではなく、音声波形そのものを直接入力として受け取り、意味レベルでダイレクトに理解する全く新しいアーキテクチャを採用しました。
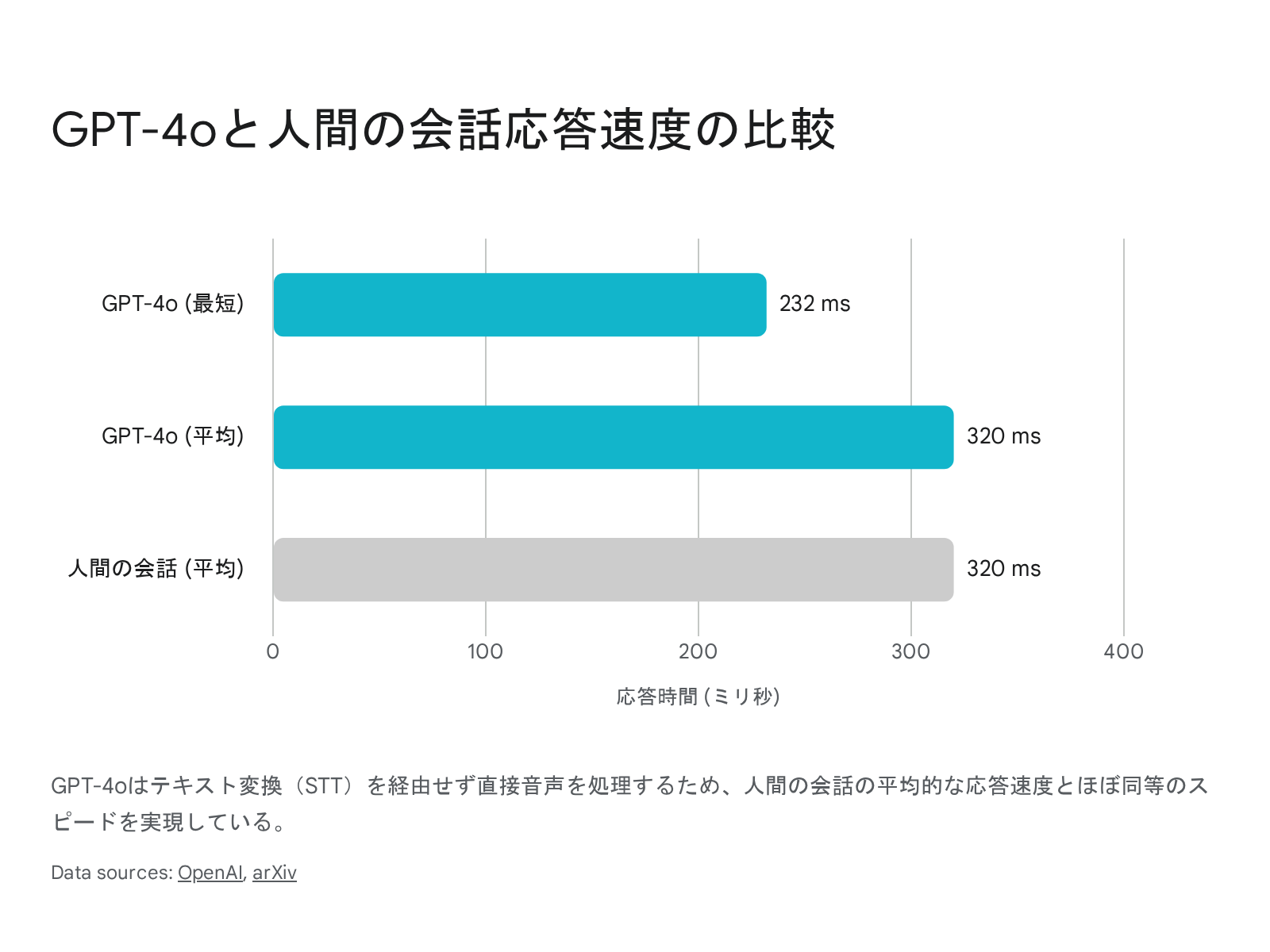
さらに、2024年にOpenAIが公開した 「GPT-4o(オムニ)」 は、音声の入出力を中間のテキスト変換を挟まずに直接処理します。これにより、最短232ミリ秒、平均320ミリ秒という、人間同士の自然な会話に近いスピードでの応答を実現しました[10]。
現場の業務は何が変わるのか?
このマルチモーダルAI技術が音声入力ツールの裏側で動くようになると、現場における使い勝手に「劇的な質的変化」が起こります。音声入力は単なる「文字起こしの道具」から、現場の状況を把握して「人間の意図を深く理解するパートナー」へと進化するのです。
具体的に、明日からの現場で以下のような使い方が可能になります。
- 深い文脈の理解と保持: 「さっき入力した数値を35に修正して」と指示しただけで、AIは直前の作業内容や会話全体の文脈を保持しているため、どの点検帳票の、どの項目のことを指しているのかを正確に推論し、該当箇所のみを適切に上書き修正します。
- 専門用語の文脈補完: 建設業界や製造業界特有のマニアックな専門用語や略語、あるいは工場内だけのローカルな隠語であっても、前後の文脈や作業内容から「現在の点検プロセスなら、この音はあの専門用語を指しているはずだ」と推測し、正しい漢字変換で記録します。
- 複合的な指示への対応: タブレットのカメラで画像を捉えながら「この写真のサビの状況を、第2ラインの点検票の備考欄に記録しておいて」と音声で指示するだけで、AIは画像データ(視覚)と音声データ(聴覚)を同時に統合処理し、瞬時に指定された帳票の作成を完了させます。
第5章: 4つの時代を比較する
ここまで詳細に解説してきた70年にわたる音声認識技術の長大な進化の軌跡を、わかりやすく一覧表で比較してみましょう。
| 比較項目 | 第1世代: ルールベース/HMM(1952〜2000年代) | 第2世代: DNN-HMM(2012年〜) | 第3世代: End-to-End(2014年〜) | 第4世代: マルチモーダルAI(2023年〜) |
|---|---|---|---|---|
| 代表技術 | Audrey, HMM, GMM-HMM | DNN-HMM | CTC, LAS, OpenAI Whisper | Gemini, GPT-4o |
| 処理方式 | 人間が設計したルール+統計モデル | DNN+統計のツギハギ(ハイブリッド) | ニューラルネットワークによる一気通貫 | 複数モダリティ(音声・視覚等)の直接統合 |
| 認識精度 | 極めて低い(特定条件下・特定話者のみ) | 高い(静かな環境で威力を発揮) | 非常に高い(ノイズ耐性が劇的に向上) | 最も高い(文脈・意図の理解を含む) |
| 対応言語 | 単一言語・限定的な語彙のみ | 単一言語・大語彙への対応 | 多数の言語(Whisperは99言語に対応) | 多言語+多モダリティのネイティブ処理 |
| ノイズ耐性 | 非常に弱い(実用不可レベル) | やや弱い | 強い(騒音下でも実用レベル) | 非常に強い |
| 文脈理解 | 全くなし | 全くなし | 限定的(句読点挿入・フィラーの自動除去) | 会話全体の文脈・複雑な意図を深く理解 |
| 主な弱点 | 実用にはほぼすべての面で不足 | パイプライン接続部での致命的な情報損失 | テキストへの変換に特化しており意図は読めない | 計算コストが非常に高い、プライバシー管理の課題 |
この表から明らかなように、第1世代や第2世代の時代に「音声入力は現場では使い物にならない」と判断されたのは、技術的な限界から来る必然でした。しかし、第3世代のEnd-to-Endモデル以降の飛躍的な進化により、その常識は過去のものとなっています。
第6章: なぜ今、現場の音声入力は「使える」ようになったのか
製造業、物流業、建設業の現場は、静かなオフィス環境とは全く異なります。絶え間ない機械の重低音、飛び交う無線の指示、マスクや安全ヘルメットの着用など、音声認識にとっては極めて過酷な環境です。
歴史を振り返ると、これまでの音声認識が現場で敬遠されてきた理由が明確にわかります。
- 第1世代: そもそも言葉を正しく認識できず、使い物にならない。
- 第2世代: 静かな会議室では使えるが、工場の騒音下ではエラーを連発して使い物にならない。
- 第3世代: ノイズには強くなり正確に文字起こしはできるようになったが、現場特有の複雑な専門用語や、「えーっと、ここの不良箇所は…」といった人間の曖昧な発話の「真の意図」までは汲み取ってくれないため、結局後から手作業で修正する必要がある。
第4世代のAIで初めて「実用レベル」に到達した
現在、最新のマルチモーダルAIや大規模基盤モデルを活用した音声入力は、ついに現場の過酷な実務で「使える」レベルに到達しました。
現場で使えるようになった最大のブレイクスルーは 「文脈補完」と「業界知識の統合」 です。騒音の激しい工場内で音声の一部がノイズにかき消されて途切れてしまったとしても、AIは「この点検プロセスの文脈であれば、ここは『トルク値異常』と言っているはずだ」と高い精度で推論し、正しい記録を生成します。また、作業用手袋を着用していたり、手が油や泥で汚れていたりする状況下でも、端末に一切触れることなく完全なハンズフリー操作で記録作業が完結します。
厚生労働省の「令和5年版 労働経済の分析」によれば、近年の激しい労働力不足や人材定着の課題を解決するため、多くの企業が賃上げを試みています。しかし、その報告書では同時に、賃上げを継続するためには「業績の改善」や「労働生産性の向上」が不可欠であると厳しく指摘されています。人手不足が深刻化する現場において、煩雑な事務作業や報告書作成の負担をAIで軽減し、作業者が本来の現場業務に集中できる環境を整えることは、もはや待ったなしの最重要経営課題です。
「ながら記録」が現場の入力課題を根本から解決する
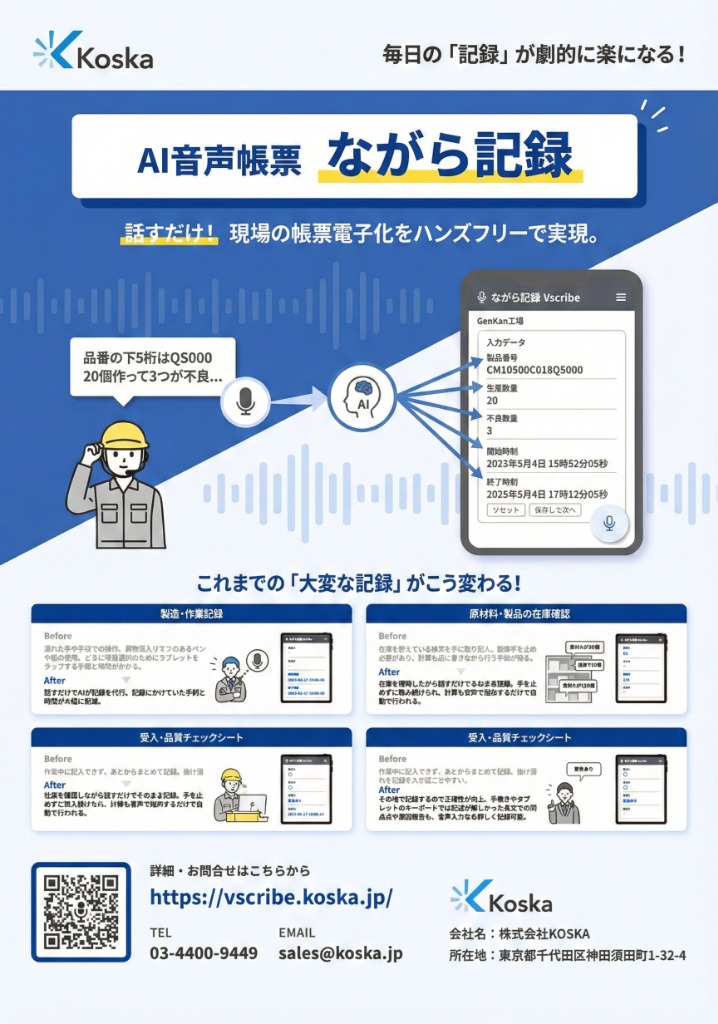
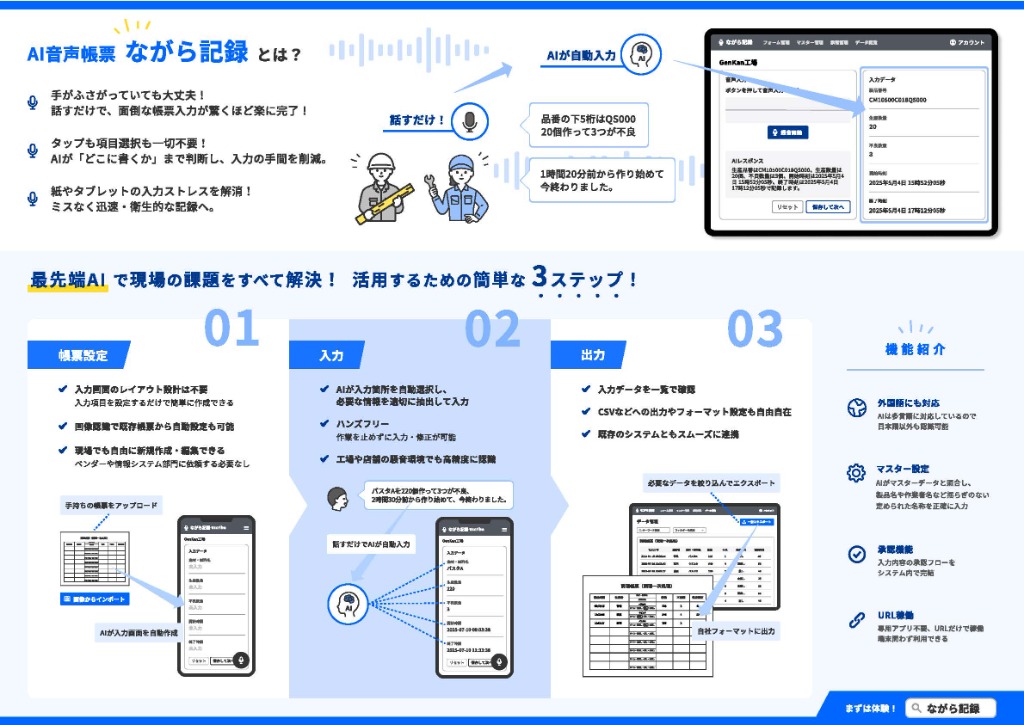
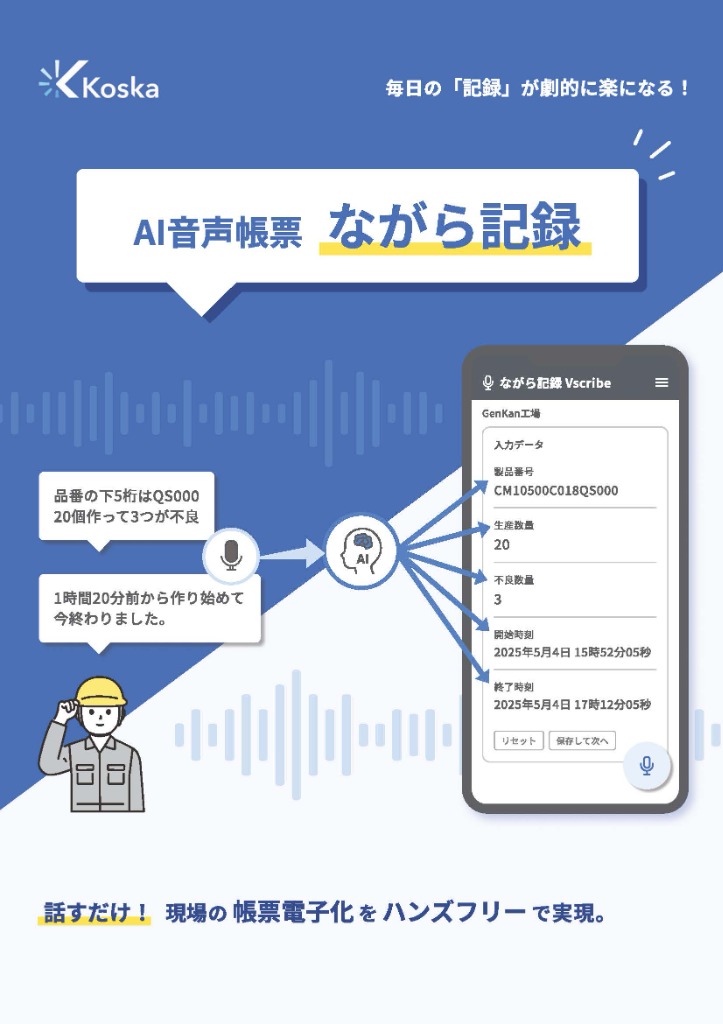
こうした最新のAI音声認識技術を、製造・物流・建設現場の業務フローに特化して最適化し、誰もが使える形に実用化したのが現場向け記録ツール 「ながら記録」 です。
このツールは、現場の作業者が「作業を止めることなく、動きながら声だけで記録する」ことを目的として徹底的に設計されています。これまでの技術史で解説してきた「圧倒的なノイズ耐性」「専門用語の深い理解」「文脈の高度な推論」というAIの恩恵を、特別な機器を導入することなく、アプリ一つで現場に導入できます。
これまでの電子帳票システムのように、現場の作業をわざわざ一旦止めて、汚れた手袋を外し、タブレットの小さな画面をちまちまとタップして入力する必要はもうありません。普段使っている既存の紙の帳票フォーマットをそのままシステムにアップロードするだけで、AIが自動で入力項目を設定します。作業者は手順に従ってマイクに向かって自然に話すだけで、AIが文脈を正確に理解し、該当する項目にテキストとして自動で振り分けて記録を完了させます。
さらに、日本語の読み書きを前提とした帳票の記入は、外国籍の作業者にとって負担になりがちです。ながら記録では、母国語で話した内容をAIが瞬時に翻訳・認識し、日本語の帳票として自動入力できるため、言語に関わらず同じ手順で記録できます。
最新のAI技術は、現場の「手が塞がっている」「記録に莫大な時間がかかる」という根本的な悩みを解決する、極めて強力で頼もしいパートナーとなっています。
FAQ: 音声認識・AI音声入力に関するよくある質問
Q: 従来の音声認識とAI音声認識の一番の違いは何ですか?
従来の音声認識は、人間が手作業で設計した音響ルールに従う「ルールベース」の手法でした。一方、AI音声認識は、膨大な音声データからディープニューラルネットワークが自ら特徴やパターンを抽出する「学習ベース」の手法です。これにより、予測精度と柔軟性が根本から変わりました。
Q: AI音声認識はどのくらいの精度がありますか?
最新のEnd-to-Endモデル(OpenAIのWhisperなど)は、標準的なテストデータセットにおいてWord Error Rate(単語エラー率)が数パーセント台まで低下しており、プロの人間による文字起こし作業に匹敵する精度を達成しています。ただし、使用する環境音や特殊なドメインにより多少の差が出る場合はあります。
Q: マルチモーダルAIの音声認識は従来と何が違いますか?
従来のAI(Whisper等)がいったん「音声をテキストに変換」してから意味を処理するのに対し、マルチモーダルAI(GPT-4oやGemini等)は音声を直接「意味レベル」でネイティブに処理します。これにより、声のトーンや感情、会話全体の文脈を含めて人間の意図を深く理解できる点が最大の違いです。
Q: 騒音のある現場でもAI音声入力は使えますか?
はい、十分に実用可能です。最新のAIモデルはインターネット上の数十万時間に及ぶノイズ混じりのデータセットで事前学習されており、工場や建設現場などの一定の騒音環境下でも、ノイズを排除し文脈から正しい単語を高精度に推定して認識します。
Q: AI音声入力を業務で導入するには何が必要ですか?
専用のシステム開発や、数百万円もするような高価な専用マイク機材は不要です。「ながら記録」のような現場特化型のクラウドツールを利用すれば、普段お使いのスマートフォンやタブレットの内蔵マイクを通じて、明日からすぐに高精度なAI音声入力を業務に組み込むことが推奨されます。
まとめ — 音声入力は「聞き取る」から「理解する」へ
70年に及ぶ音声認識技術の長大な歴史を振り返ると、そこには明確な進化の軌跡がありました。
- ルールベースの時代(1950〜90年代): HMMなどの統計的手法を用い、機械に人間の声をパターンとして覚えさせることに苦心した時代。
- ディープラーニングの導入(2012年〜): DNNの画期的な登場により、AIが自ら音の特徴を学習し、認識精度が一気に劇的向上。
- End-to-Endの確立(2014年〜): Whisperなどに代表される、音声を一気通貫でテキスト化するモデルが完成し、現場の課題であったノイズ耐性が飛躍的に向上。
- マルチモーダルAIの到来(2023年〜): 音声を直接意味として理解し、現場の文脈や専門用語を文脈から推論する真のパートナーへと進化。
「音声入力は誤変換ばかりで使い物にならない」という認識は、もはや過去の話です。現在のAI音声入力は、単なるテキスト変換ツールを遥かに超え、現場の文脈や人間の意図を正確に汲み取る高度なシステムへと変貌を遂げました。現場の負担を減らし、限られた人員でも無理なく業務を回せるよう支える武器として、今まさに導入すべき成熟した技術だと言えます。
AI音声入力を実際の現場で試してみたい方、タブレット入力の手間を抜本的に削減したいとお考えの現場責任者の方は、ぜひ「ながら記録」の資料をダウンロードし、その圧倒的な精度と現場に寄り添った利便性を体感してください。
1 出典 Davis, K. H., Biddulph, R., & Balashek, S. (1952). Automatic Recognition of Spoken Digits. The Journal of the Acoustical Society of America. 元の記事を読む — asa.scitation.org 2 出典 Rabiner, L. R. (1989). A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE. 元の記事を読む — ieeexplore.ieee.org 3 出典 Hinton, G. E., Osindero, S., & Teh, Y-W. (2006). A Fast Learning Algorithm for Deep Belief Nets. Neural Computation. 元の記事を読む — direct.mit.edu 4 出典 Hinton, G., Deng, L., Yu, D., et al. (2012). Deep Neural Networks for Acoustic Modeling in Speech Recognition. IEEE Signal Processing Magazine. 元の記事を読む — ieeexplore.ieee.org 5 出典 Graves, A., & Jaitly, N. (2014). Towards End-to-End Speech Recognition with Recurrent Neural Networks. ICML. 元の記事を読む — proceedings.mlr.press 6 出典 Chan, W., Jaitly, N., Le, Q., & Vinyals, O. (2016). Listen, Attend and Spell. ICASSP 2016. 元の記事を読む — ieeexplore.ieee.org 7 出典 Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need. NeurIPS. 元の記事を読む — papers.nips.cc 8 出典 Radford, A., Kim, J. W., Xu, T., et al. (2022). Robust Speech Recognition via Large-Scale Weak Supervision. arXiv. 元の記事を読む — arxiv.org 9 出典 Gemini Team, Google DeepMind. (2023). Gemini: A Family of Highly Capable Multimodal Models. arXiv. 元の記事を読む — arxiv.org 10 出典 OpenAI. (2024). GPT-4o System Card. OpenAI Technical Report. 元の記事を読む — openai.com 11 出典 厚生労働省. (2023). 令和5年版 労働経済の分析 ―持続的な賃上げに向けて―. 元の記事を読む — mhlw.go.jp